
Synthetic Data Explained
🧠 Knowledge Series #57: Everything you need to know. Examples from Uber, Spotify, Tesla. Tools and terminology and opportunities for product teams.
🔒The Knowledge Series is available for paid subscribers. Get full ongoing access to 50+ explainers and tutorials to grow your tech knowledge at work. New guides added every month.
Hi product people 👋,
OpenAI’s former chief scientist predicts that we’ve reached “peak data” and new research from Epoch predicts that AI models will run out of data to use for training by 2028. But in the absence of real-world training data, more and more tech companies are turning to synthetic data to speed up development times and reduce costs.
But synthetic data is not just helpful for training AI models; product teams can use synthetic data at work to enhance their products in ways that were unimaginable just a few years ago. One startup even allows product teams to conduct user testing without real humans.
In this Knowledge Series, we’ll explore what synthetic data is, how it works and how you can use synthetic data in the product development process with some real world applications from companies like Uber, Grammarly, Spotify and more that you can use for inspiration.
Coming up:
What exactly is synthetic data and how does it work?
How synthetic data can help you speed up user testing, feature development, market research and more
Real world examples of how companies are using synthetic data in their product processes including: Uber, Spotify, JP Morgan, Grammarly and more
Tools and new synthetic data companies you can use

What is synthetic data?
Synthetic data is artificially generated information, designed to mimic real world data. As you can see, it’s quickly becoming an area of interest for many:

It can come in many forms, but three of some of the most common forms include:
Tabular data which follows a specific format as you might expect in a typical database.
Fully synthetic data generated entirely from scratch. The data mimics the properties from the original data while at the same time ensuring that no real world data is present.
Partially synthetic where both synthetic and real world data work together, typically to protect security and enhance privacy
To help explain what synthetic data is, here’s a comparison table which shows you the core differences between real data, dummy data and synthetic data:

Why synthetic data is useful
Putting aside the fact that we’re running out of real world data sources to use to train AI, there are also some strong practical reasons for using synthetic data.
The most important of these is probably privacy. Anyone who has worked on the implementation of major pieces of privacy legislation like CCPA, GDPR or other similar laws knows that the protection of user data in product development is now critical.
But what if there was no risk of exposing personally identifiable information (PII) in the first place?
This is the pitch that many synthetic data startups are making. And for larger companies or industries like healthcare and finance, where the risks for data breaches are highest, this is a compelling pitch. The use of synthetic data can in theory, reduce the risk of privacy breaches since it’s artificially generated.
It’s also a lot cheaper; one AI startup, Writer, claims its latest model, which was developed using almost entirely synthetic sources, cost just $700,000 to develop — compared to estimates of $4.6 million for a comparably sized OpenAI model.
How synthetic data works - a simple explanation
Before we take a look at some practical ways you can use synthetic data during the product development process, here’s a simple overview of the key steps involved in the creation of synthetic data:
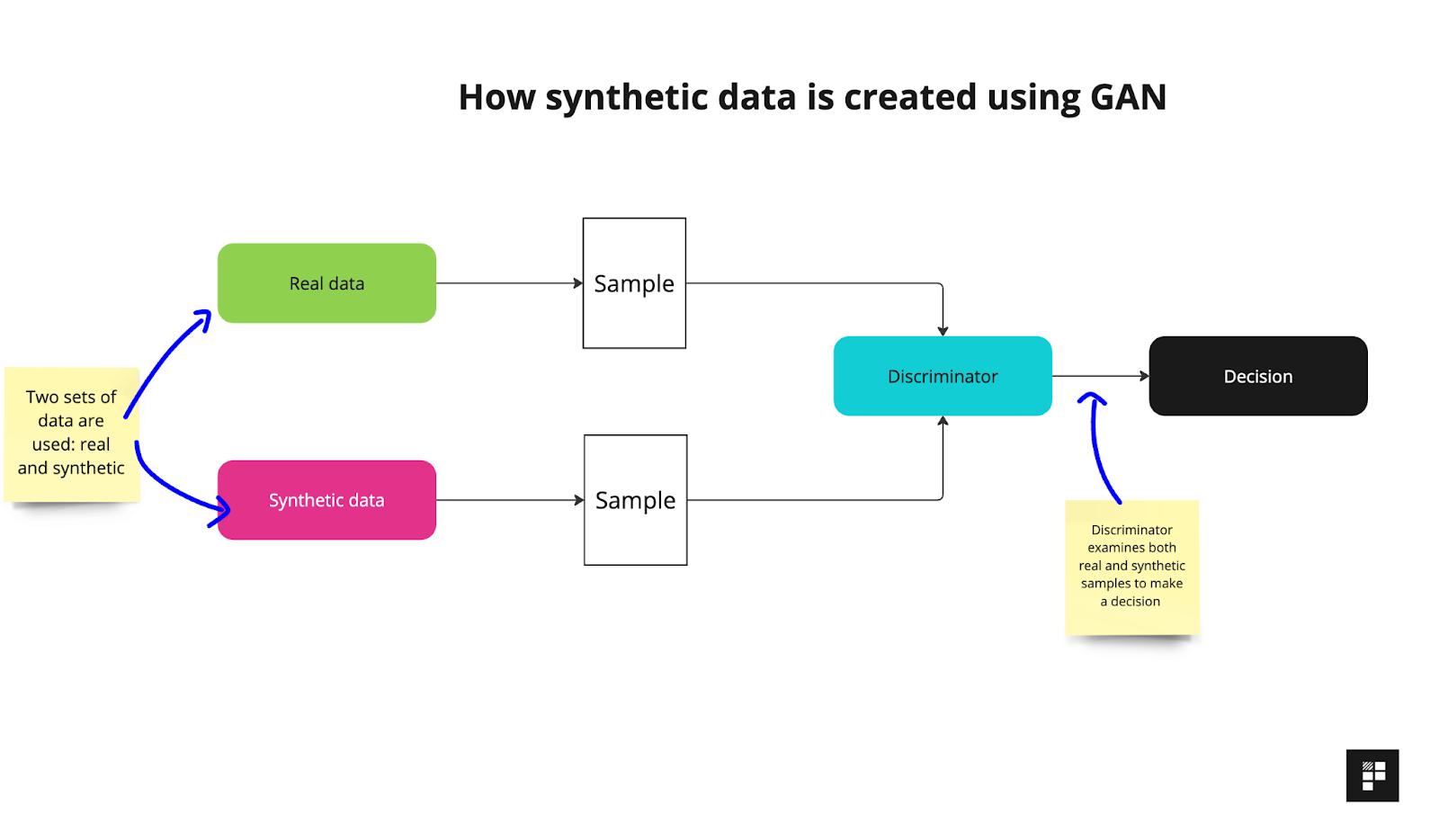
There are various different methods for creating synthetic data but one of the most popular is a process which uses Generative Adversarial Networks.
This method involves a generator which creates synthetic data and a discriminator that attempts to distinguish between the real and synthetic data.
These are generative because they’re designed to generate new data including images, text or other types of content. And they’re adversarial because they are competitive in nature; the generator attempts to create synthetic data to trick the discriminator - and in this sense, they are competing against each other.
Practical ways you can use synthetic data at work - opportunities for product teams
Now that we know a little bit about the basics of how the synthetic data generation process works, let’s explore some of the practical, real world applications of synthetic data using leading companies as inspiration.