


🧠 Knowledge Series #30: ETL and data warehouses explained
ETL, data warehouses, pipelines and more explained
🔒The Knowledge Series is a collection of easy to read guides designed to help you plug the gaps in your tech knowledge so that you feel more confident when chatting to colleagues. Clearly explained in plain English. One topic at a time.
If you’re a free subscriber and you’d like to upgrade to unlock them you can do so below. Or you can learn more about what you get with paid access here.
Hi product people 👋,
If you’ve worked on data analysis and reporting, you’ve probably come across the term ‘ETL’ but unless you’re a data scientist or engineer yourself, you might not know much about what it means.
In this Knowledge Series, we’re going to explore everything you need to know about ETL, what it is, why teams use it and how it fits into the wider data analysis world so that the next time someone in your team mentions it, you’ll be fully up to speed with how it works.
Coming up:
Databases explained - a quick recap
What is ETL and how does it work?
When and why might you want to use ETL? Real world examples from Slack, LinkedIn, Meta
How to write an ETL operation - the important bits worth knowing
ETLs and data warehouses explained
Potential risks and downsides to the ETL approach
Tools you can use

Databases explained - a quick recap
But first, before we get into the details on ETL, let’s give ourselves a quick recap on databases to help us contextualise where ETL fits into the wider picture on data analysis.
We covered databases in one of our previous editions of the Knowledge Series but one of the most important things to know about databases is the two main types of databases that exist and how they work.

SQL databases
SQL databases are highly structured and are still the most popular type of database. Postgres is the SQL database used by most professional engineering teams, followed by MySQL.
In simple terms, the "relational" aspect in a relational database refers to the way data is structured and interrelated. In this model, data is organized into tables (also known as relations), which are made up of rows and columns. Each row (a record) represents a single, implicitly structured data item, and each column represents a specific attribute of that data.
NoSQL databases
NoSQL gets rid of the table-based structure and instead uses a more fluid, flexible structure that can change over time.
The most common NoSQL database is MongoDB. MongoDB stores information in documents rather than tables.
Having a basic understanding of databases will help us to understand how an ETL pipeline gets built. More on that later. So what exactly is ETL and how does it work?
What is ETL and how does ETL work?
ETL stands for extract, transform, load. It’s a type of data integration process used by data science and product teams which allows them to take data from multiple sources, transform it (or clean it up) and then load it into a centralised location where it can be sliced and diced for further analysis.
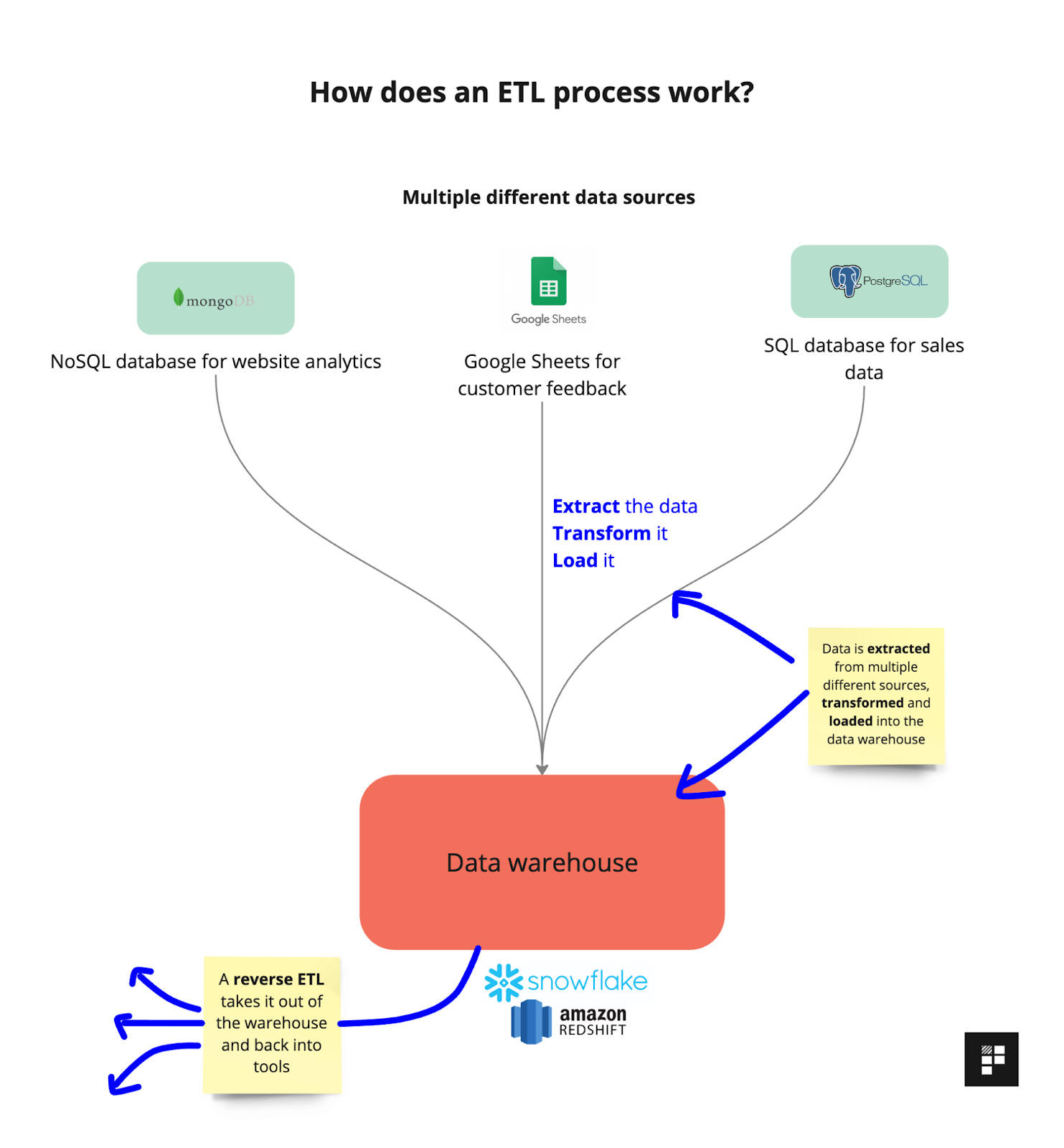
ETL is commonly used by data science and engineering teams to boost a company’s reporting capabilities - especially when data is stored in disparate, disconnected systems.
Here’s what happens during each part of the ETL process: